
Linear Regression ve Örnek Uygulama
Yazı dizimizin bu bölümün de makine ögrenmesi algoritmalarından olan regression modelini inceleyeceğiz. Makine öğrenmesi bilindiği üzere supervised,unsupervised ve reinforcement olarak üçe ayrılır. Terim olarak supervised, gözetimli ögrenme olarak adlandırılır. Sistem farklı veriler ile beslenerek oluşturulan modelin sonuçları hedef çıktılar ile karşılaştırılır. Oluşan hatalar sistem tarafından minimize edilmeye çalışılır. Temel olarak aslında veri seti içerisinde verimizin çıktılarını karşılaştıracağımız sonuçlar mevcuttur.
Linear Regression
Linear Regression supervised modeldir. Linear Regression da amaç doğrusal bir çizgi ile oluşturulacak metod “fit” edilmesine linear regression denir.
Bir değişken artarken başka bir değişkenin artması, ikili arasında ilişki kurulması olayı linear regression da ortaya çıkmıştır.
Amaçlardan bir tanesi bağımlı ve bağımsız değişken arasındaki ilişkiyi ifade eden doğrusal fonksiyonu bulmaktır. Makine ögrenmesinin temelinde veriden tahminde bulunma olayı linear regression için de geçerlidir.
Linear regression matematik formülüne bakacak olursak;
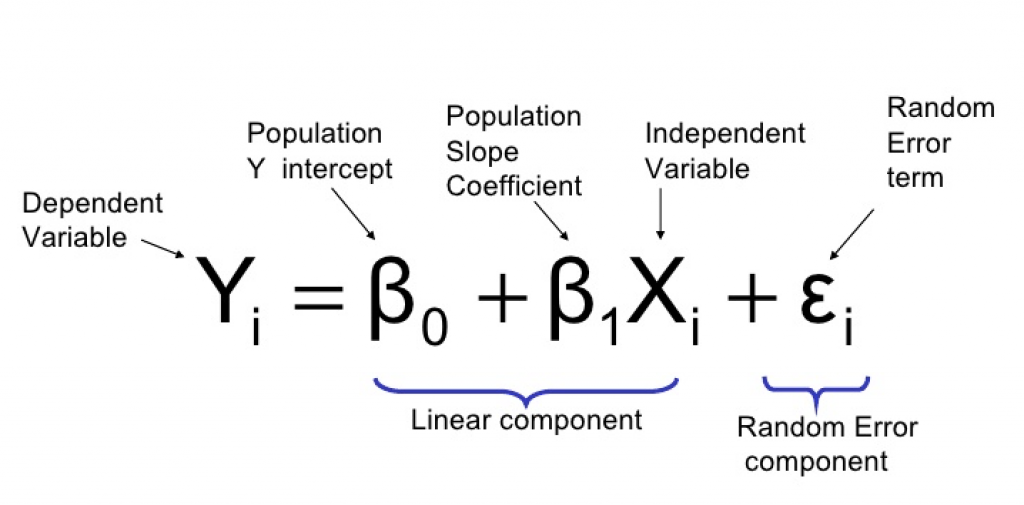
Burada bakıldığında;
- yi = bağımlı değişken (elde edilmek istenen sonuç), tahmin
- b0 = sabit değer (constant), aynı zaman da y eksenini kestiği nokta
- b1 = kat sayı(coefficient), çizilecek doğrunun eğimi
- x1 = bağımsız değişken
- E = hata tahmini
Bakıldığında makine ögrenmesi algoritmaları formülsel olarak göz korkutsa da örnek üzerinde daha anlaşılır olmaktadır. Bunu bir örnek üzerinden anlatacak olursak; Günlere bağlı dolar tahmininde bulunmak istediğinizi düşünelim. Bu örnekde bağımsız değişken “günler(yani “x1″)” olmaktadır. Bağımlı değişken ise “dolar(yani “yi”)” olmaktadır. Dolar neticede bazı iç ve dış etkenlere göre değişiklik göstermektedir. Faiz kararları,politik sorunlar vb.
Linear regression algoritmasının en temelinde verilerin en iyi doğru modeline ulaşmaktır. Noktalara en yakın geçen doğruyu çizebilmek amaçları arasındadır.

Tüm bu anlatılanları örnek python kodu yazarak pekiştirelim.
Kullanılan veri seti linear regression için internet ortamında rahatlıkla bulunabilir. Veri seti hakkında genel bilgi verecek olursak Americadaki ortalama konut fiyatlarını barındırmaktadır.

Linear Regression modeli için temel seviyede gerekli kütüphaneler yüklenir.
Not: Tüm code blogunu Jupyter Notebook üzerinde çalıştırılmıştır. Siz kendi localinizde çalıştırmak isterseniz benim gibi jupyter notebook kullanabilir veya spyder ide de kullanabilirsiniz.


Veri seti pandas kütüphanesi yardımı ile yüklenir. Genel veri seti hakkında bilgi almak için “info()” fonksiyonu kullanılır. Görüldüğü üzere 5000 satırdan oluşan, 7 kolonu olan ve içerisinde float,object barındıran bir veri seti.
Genel bilgi ediliminden sonra “describe()” fonksiyonu ile istatistiksel olarak veri seti incelenir. Veri2nin standart sapma degerleri, sayısı, orta değeri vb. bilgiler edinilir.
“columns()” fonksiyonu ile de veri seti içerisindeki kolon isimleri öğrenilir.



Bu bölümde ver setini daha iyi anlayabilmek için veri görselleştirme kütüphanesi kullanılır. Burada “seaborn” kütüphanesi kullanılmıştır. Seaborn kütüphanesine ait “pairplot” gösterimi kullanılmasında ki amaç veriler arasındaki kolaresyonu göstermek için kullanılır. Kısaca kolerasyon; olasılık kuramı ve istatistikte iki veya daha fazla raslantısal değişken arasındaki doğrusal ilişkinin yönünü ve gücünü gösterir.
Diğer bir görsel olan “heatmap” de yine benzer şekilde veriler arasındaki kolerasyonu gösterir ve bu degerleri 0 ile 1 arasında değere otutturur. Elde edilen değer ne kadar 1 degerine yakın ise iki veri arasında yüksek kolerasyon var demektir. Kullanılmış olan veri setinde incelendiğinde konutu görmeye gelenlerin fiyatla 0.64 lük bir kolaresyonu görülmektedir.




Veri görselleştirme işlemi de tamamlandıktan sonra artık veriyi modele sokmadan önce temizleme ve düzenleme aşaması gelmektedir. Burada “X” değişkenine tahminde bulunacağımız kolon yani price kolonu çıkartılarak belirtilen değere kalan kolonlar aktarılmıştır. Tahminde bulunacağımız price kolonu ise “Y” değişkenine atanmıştır.
Verimizi train ve test olmak üzere ikiye bölmek için “sklearn” kütüphanesi kullanılmış olup “train_test_split” metodu eklenmiştir. Burada dikkat edilmesi gereken “test_size” belirlemek olacaktır. sklearn default olarak eğitilecek değer(0.77) ile tahmin degerini(0.33) olarak belirlemektedir. “random_state” ise her seferinde veri setinde aynı veya farklı verilerin ögrenilmesi için kullanılır.

Veri ile alakalı tüm işlemler tamamlandığında artık model oluşturulmaya geçilir. Yine sklearn kütüphanesinin “LinearRegression” metodu eklenir. Metod eklendikten sonra “fit” fonksiyonu ile eğitilecek yani train verilerimiz modele verilir.

Makine Ögrenme işlemi tamamlandıktan sonra artık tahmin bölümüne geçebiliriz. Burada “predict” fonksiyonu kullanılır. Görselde görüldügü üzere tahmin degerlerim ve veri seti içerisinde karşılaştırma yapabileceğim değerler gösterilmektedir.

Veri seti içerisindeki değerler ile tahmin değerlerimin gösterminde dogrusal fit edilmiş çizgi görülmektedir.

Son olarak yine sklearn kütüphanesi kullanarak metric degerlerine bakılır. “mean_absolute_error” ve “mean_squared_error” istatiksel olarak performan ölçümleri için kullanılır. “mean_absolute_error” hatanın mutlak ortalaması olarak nitelendirilir. “mean_squared_error” ise hatanın karaler ortalaması olarak nitelendirilir. Hata degerinin büyüklükleri ortak ise MSE kullanılır.
Bu yazı dizimizin sonuna geldik. Herkese faydalı olması dileğiyle. İyi Okumalar.

- Doğal Dil İşleme ile Özet Çıkarma - Mayıs 20, 2022
- K-NN ve Örnek Uygulama - Ocak 18, 2021
- Polynomial Regression ve Örnek Uygulama - Ocak 6, 2021



1 Response
[…] mean_absolute_error ve mean_squared_error istatiksel olarak performans ölçümleri için kullanılır. mean_absolute_error hatanın mutlak ortalaması olarak nitelendirilir. mean_squared_error ise hatanın kareler ortalaması olarak nitelendirilir. Hata değerinin büyüklükleri ortak ise “mse” kullanılır (Kaynak: Ensar Erdoğan). […]