
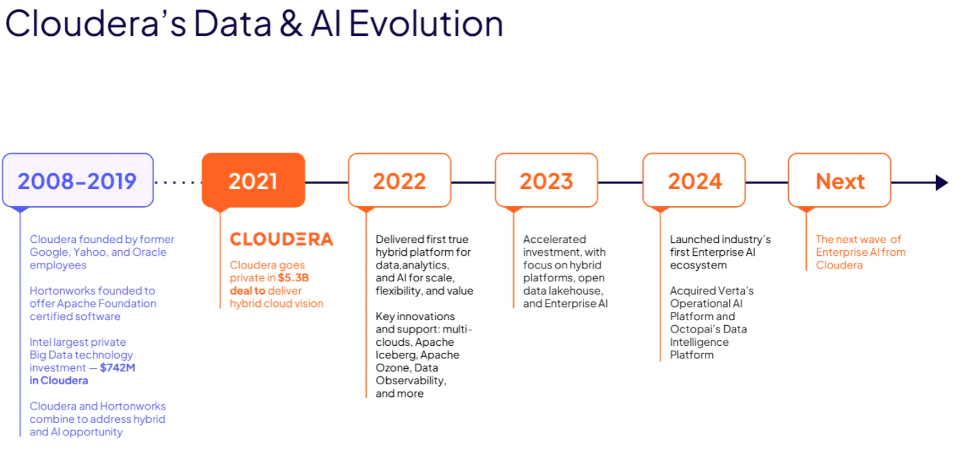
Cloudera’nın Evrimi
1.Giriş
Cloudera… Bazıları tarafından hala, open source teknolojileri paketleyip enterprise seviyede kullanıma sunan bir şirket olarak algılansa da, gerçek bunun çok ötesinde. Özellikle 2010’lu yılların sonunda yaptığı satın alımlar ve 2020’li yılların başında gerçekleştirdiği vizyoner hamleler ile kendi tanımı ile bir Enterprise Data Cloud şirketine dönüşmüş durumda. Bu yazıda Cloudera’nın “Hadoop dağıtımı” kimliğinden çıkıp bugün geldiği hybrid enterprise data cloud platform noktasını özetlemeye çalışacağım. Cloudera ekosistemini anlamaya çalışırken, aslında yalnızca bir ürün ailesini değil, son 20 yılda veri platformlarının nasıl evrimleştiğini de anlamış olacağız.
2.Cloudera CDH
Başlangıç noktası 2000’lerin başında, Google’ın yayınladığı GFS (Google File System) ve MapReduce makalelerine dayanıyor. Bu makaleler sayesinde, modern distributed data processing dünyasının temeli atılmış oldu. Hadoop ekosistemi bu fikirlerin open-source karşılığı olarak doğdu. Cloudera ise bu open-source dünyayı enterprise’a taşıyan ilk şirketlerden biri oldu. Buradaki kritik kırılım şu: Hadoop sadece bir teknoloji değil, “commodity hardware üzerinde distributed computation” fikrinin de enterprise dünyaya girişiydi. Bu gelişme de özellikle bankalar, telekom şirketleri ve büyük ölçekli organizasyonlar için veri işleme maliyetini dramatik şekilde düşürdü.
Cloudera’nın ilk ürünü olan CDH (Cloudera Distributed Hadoop), aslında Hadoop ekosisteminin kurumsallaştırılmış haliydi. HDFS ile distributed storage, YARN ile resource management ve Hive/Impala ile SQL katmanı sağlanıyordu. Ancak bu yapı monolitikti. Storage ve compute tightly birbirine bağlıydı, cluster büyüdükçe yönetim karmaşıklığı artıyordu ve gerçek zamanlı kullanım senaryoları sınırlıydı. Bu dönemde veri platformları daha çok batch processing odaklıydı; yani veri toplanır, saatler veya günler sonra işlenir ve raporlanırdı.
Aynı dönemde Hortonworks HDP ile tamamen open-source yaklaşımı savunuyordu. Cloudera daha enterprise feature’lara (örneğin Cloudera Manager) odaklanırken, Hortonworks Apache ekosistemine birebir bağlı kalıyordu. Bu iki yaklaşım yıllarca rekabet etti ancak 2019’da gerçekleşen birleşme aslında bir dönemin kapanışıydı. Bu birleşme, Hadoop ekosisteminin kendi içinde rekabet etmek yerine, yeni rakip olan cloud-native veri platformlarına karşı konumlanması gerektiğini gösterdi. Yani savaş Hadoop vendor’ları arasında değil, Hadoop vs cloud platformlar arasında olmaya başladı.
3.Cloudera CDP
Bu birleşme kritik bir dönüm noktası oldu. Bu birleşmeden sonra Cloudera’nın stratejisi tamamen değişti ve CDP (Cloudera Data Platform) ortaya çıktı. CDP ile birlikte en önemli mimari dönüşüm şu oldu: compute ve storage ayrıştırıldı (decoupling). Artık veri object storage üzerinde tutulabilir ve compute katmanı ihtiyaca göre elastik olarak ölçeklenebilir duruma geldi. CDP ile klasik Hadoop cluster mantığında köklü değişiklikler meydana geldi. YARN tabanlı resource yönetimi yerini giderek Kubernetes tabanlı execution modeline bırakmaya başladı. Bu değişim, Cloudera’yı bir “Hadoop dağıtımı” olmaktan çıkarıp, gerçek anlamda bir enterprise data platform haline getirme yolunda temel değişikliklerden biri oldu.
Bu noktada Cloudera’nın kendini tanımladığı “Enterprise Data Cloud” kavramı devreye giriyor. Bu kavramın dört temel karakteristiği var ve bunları yüzeysel değil, mimari açıdan okumak gerekiyor. Hybrid ve multi-cloud yaklaşımı, verinin tek bir lokasyonda yaşamayacağını kabul eder. Özellikle bankacılık gibi regüle sektörlerde bazı veriler on-prem kalmak zorundadır. Aynı anda analytics workload’larının cloud’da çalışması gerekir. Cloudera bu iki dünyayı tek bir control plane ile yönetmeyi hedefler. Bu, veri mimarisinde “data gravity” problemini minimize etmeye yönelik bir yaklaşımdır.
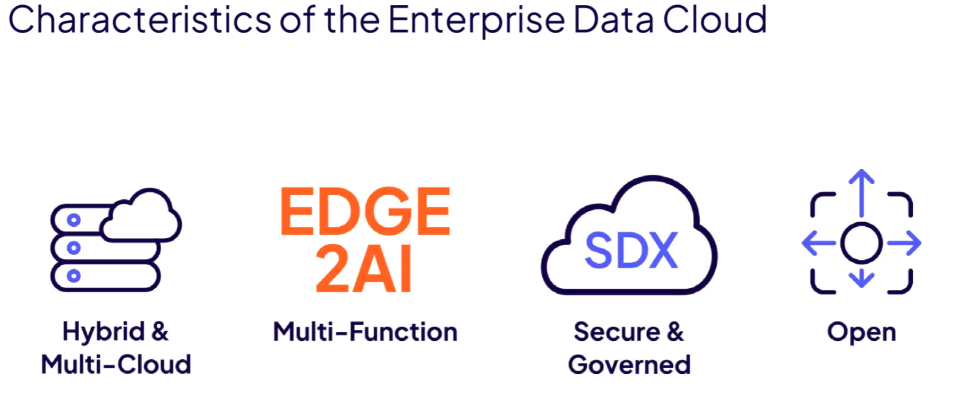
Multi-function yaklaşımı ise platformun sadece bir workload için değil, farklı kullanıcı profilleri için hizmet vermesi anlamına gelir. Data engineer, data analyst ve data scientist aynı platform üzerinde çalışabilir. Bu noktada platformun batch (Spark), interactive SQL (Impala), streaming (Kafka/Flink) ve machine learning (Cloudera AI) workload’larını birlikte desteklemesi gerekir. Bu, modern veri platformlarının en kritik gereksinimlerinden biridir çünkü veri artık sadece raporlama için değil, operasyonel kararlar için de kullanılmaktadır.
Güvenlik ve governance katmanı olan SDX (Shared Data Experience), Cloudera’nın en güçlü yönlerinden biridir. CDH döneminde güvenlik, metadata ve lineage parçalı yapılardı. CDP ile birlikte bu katman merkezi hale getirildi. Bu sayede lineage (verinin nereden geldiği ve nasıl dönüştüğü), access control ve compliance tek bir model üzerinden yönetilebilir. Özellikle GDPR ve benzeri regülasyonlar düşünüldüğünde bu katman artık opsiyonel değil, zorunludur.
Açıklık (openness) ise Cloudera’nın stratejik olarak vendor lock-in’e karşı konumlandığını gösteriyor. Iceberg gibi open table format’ların desteklenmesi, Spark ve Hive gibi open engine’lerin kullanılması bu yaklaşımın bir parçasıdır. Bu noktada Cloudera kendini Databricks gibi daha kapalı çözümlerden ayrıştırır.
Cloudera’nın günlük hayattaki etkisini anlamak için verilen use-case’lere bakmak önemli. Predictive maintenance, fraud detection, telco analytics veya pharma research gibi senaryolar aslında modern veri platformlarının neden var olduğunu gösterir. Buradaki ortak nokta şudur: veri artık sadece geçmişi anlamak için değil, geleceği tahmin etmek ve anlık aksiyon almak için kullanılır. Bu da bizi streaming ve IoT tarafına götürür. Geleneksel batch sistemlerde veri gecikmeli işlenirken, modern sistemlerde veri akışı gerçek zamanlıdır. Kafka, NiFi ve Flink gibi teknolojiler bu dönüşümün merkezindedir.
Bu dönüşüm veri lifecycle’ını da değiştirmiştir. Artık veri sadece ingest edilip analiz edilmez; ingest, prepare, analyze, serve ve predict aşamalarından oluşan uçtan uca bir pipeline söz konusudur. Bu pipeline’ın altında güvenlik, yönetişim, lineage ve otomasyon katmanları sürekli çalışır. Bu yapı aslında modern data platformların işletim sistemi gibidir.
4.Cloudera Enterprise Data Plaform
2026 perspektifinden baktığımızda Cloudera’nın vizyonu daha da netleşiyor. Hadoop artık merkezde değil. Onun yerini Iceberg gibi modern table format’lar, Kubernetes tabanlı compute ve streaming-first mimariler alıyor. Cloudera’nın yöneldiği yapı aslında klasik data warehouse veya data lake kavramlarının ötesinde bir lakehouse + data fabric + AI platform birleşimidir. SDX katmanı veri fabric yaklaşımını desteklerken, farklı domain’lerin kendi verilerini yönetebilmesi data mesh prensipleriyle uyumludur.
Aynı zamanda platformun AI ile entegrasyonu giderek artıyor. Cloudera AI, MLOps süreçleri, feature store yapıları ve real-time inference gibi konular artık platformun doğal parçaları haline geliyor. Bu da Cloudera’yı klasik bir veri platformundan çıkarıp, AI-native data platform kategorisine yaklaştırıyor.
Sonuç olarak Cloudera’nın evrimi şu şekilde okunabilir: başlangıçta Hadoop ile batch processing problemi çözüldü, ardından farklı workload’lar tek platformda birleştirildi, sonrasında cloud ile birlikte platform esnek hale geldi ve bugün AI ile birlikte veri platformu karar mekanizmalarının merkezine yerleşti. Artık bigdata profesyonelleri için önemli olan da sadece Hadoop bilmek değil, bu dönüşümün tamamını anlayıp mimari olarak anlamlandırabilmektir.

- Data Lifecycle with Cloudera - Mayıs 12, 2026
- Cloudera Architecture - Mayıs 6, 2026
- Cloudera’nın Evrimi - Nisan 30, 2026


